
INTEXT Process
To access this process:
- Enter "INTEXT" into the Command Line and press <ENTER>.
-
Display the Find Command screen, locate INTEXT and click Run.
See this process in the Command Table.
Process Overview
Import a text file with a known data definition to create a Datamine binary file (either .dm or .dmx, depending on your current default file format.
A data definition can either be determined from the header of the imported file, or from an existing Datamine binary file. If a separate file (INDD) is used, INTEXT attempts to calculate the type and (in the case of alphanumerics) size of the columns of the output file.
Several parameters are available to control the conversion process.
INTEXT is used by the Text Importer tool, where many of the settings listed below appear as curated screen controls.
Datamine data is generated in the current default Datamine File Formats.
Note: Data records may not start with the character "!". This is because the ! symbol acts as the end-of-data character. However, macro files, where the command starts with !, may be read if a blank is inserted prior to the ! symbol.
SETTINGS and INDD Inputs
The SETTINGS optional input file is used to provide additional information to support the Data Definition (INDD) file, such as alphanumeric column widths, included or excluded fields and names of output fields if different to the input data. If INDD is not specified, SETTINGS is ignored.
*INDD
The INDD file is, in effect, a prototype file containing a header (other data is ignored). Just like a prototype block model file, INDD contains field definitions of the data being imported. "INDD" stands for "input data definition".
Typically, the INDD file, representing incoming data
For example, if importing block model data, the following definition matches the tabular data held in a text file:

*SETTINGS
For the same import, the SETTINGS file determines how the incoming data attribute names are mapped to output names. In this case, you may want the cell size attributes (Xinc, Yinc, Zinc) to be capitalized in the DM file, and to ensure the expected system fields for a block model are present, convert X to XC, Y to YC and Z to ZC. In this case, the SETTINGS file looks like this:
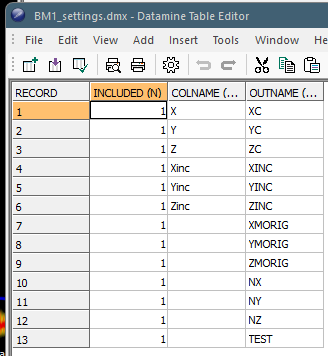
The SETTINGS file can contain any or all of the following attributes:
-
COLWIDTH – The alphanumeric column width to be created in the output Datamine file. This is either 0 (a column width
COLWIDTH must be a positive integer, other than the final column that can be set to a negative value, meaning the COLWIDTH is set to the width of the all characters available.
Note: This field is mandatory if FIXWIDTH=1.
-
INCLUDED – 1 if the incoming field is included in the importation, or 0 if it is ignored.
-
OUTNAME – The output Datamine field name of an imported field (as shown in COLNAME for the same record).
-
COLNAME – The name of the field in the imported text file that will be changed to OUTNAME during conversion.
Note: Where a field isn't specified, no data conversion occurs and the incoming data assumes default settings (default column width, included, input name = output name).
Input Files
|
Name |
Description |
I/O Status |
Required |
Type |
|
INDD |
File containing Data Definition. |
Input |
No |
Table |
| SETTINGS |
File providing settings for each imported data column, with up to four optional fields. See "SETTINGS and INDD inputs", above. |
Input | No | Table |
Output Files
|
Name |
I/O Status |
Required |
Type |
Description |
|
OUT |
Output |
Yes |
Table |
File to be created. |
Parameters
|
Name |
Description |
Required |
Default |
Range |
Values |
|
COLUMN |
Define the column separator in the input text file.
|
No |
1 |
1,5 |
1,2,3,4,5 |
| DELIMIT |
Treat consecutive delimiters as one.
|
No | 0 | 0,1 | 0,1 |
| FIXWIDTH |
Import data as fixed width columns. If FIXWIDTH=1 then SETTINGS must exist and contain a list of column widths for all importable fields (COLWIDTH attribute). If FIXWIDTH = 0, the column width is variable, and set according to the data in the imported file. |
||||
| STARTROW | Row number in input text file of the first record to import. | No | 1 | Undefined | Undefined |
| ENDROW |
Row number in input text file of the last record to import. Default=+, i.e. read all rows. 0 or negative will also be treated as read all rows. |
No | "+" | Undefined | Undefined |
| HEADER |
Row number in input text file that contains the field names. If no header is set, then the input data defintion (INDD) is required (see also ALLCOL). 0 or negative is treated as no header. |
No | 1 | Undefined | Undefined |
| UPCASE |
Force all field names to be upper case. Note that if the data definition or input file contains multiple variations of a field name case, and UPCASE = 1, the import will stop.
|
No | 0 | Undefined | Undefined |
| DECIMAL |
Specify whether numbers use decimal points or commas.
|
No | 0 | 0,1 | 0,1 |
| QUOTESTR |
Single character used to quote strings in the imported data. The value can either be an integer code or a single character. Integer codes: 0 – no quotes 1 – double quotes (") 2 – single quote (') Any column separator (according to COLUMN) found inside a quoted string is considered a normal text character. Note: Multiline strings are not supported. |
||||
| COMMENT |
Single character used to identify comment lines in the incoming file. Any line starting with this character is ignored. The value can either be an integer code or single character. Integer codes: 0 – no comment 1 – # character |
||||
| INCRMNT | Only read every 1 of INCRMNT records / rows, starting from STARTROW. | No | 1 | Undefined | Undefined |
| ABSENT | Character string or number that defines absent data. | No | "-" | Undefined | Undefined |
| TRACEDAT | A value that represents a trace numeric value. If this value is detected, it is assigned the system "TR" flag in the numeric field of the output file. | ||||
| CEILING | Character string or number that defines ceiling data. | No | "+" | Undefined | Undefined |
| ALLCOL |
Only used if INDD is specified. Import all columns even if these do not exist in Data Definition.
|
No | 0 | 0,1 | 0,1 |
| NSCAN |
Number of records to read to auto detect field types and lengths. Not used if IN is defined and HEADER is 0 or negative. If 0, let the process determine the appropriate number of rows to scan according to the file size. |
No | 0 | Undefined | Undefined |
| WORLDXYZ |
This parameter is only used when importing block model. It is mainly designed for rotated block model when the incoming coordinates are not local grid coordinates as expected, but world (or mine local) coordinates. In this case use the value 1. =1 : if you know that the XC,YC,ZC come as world coordinates. =0 : if you know that the XC,YC,ZC come as grid local coordinates. =-1 : let the process choose (local grid coordinates for rotated block models, world coordinates otherwise) (default). |
No | -1 | -1,1 | -1,0,1 |
Example
In the following example, the CSV file for conversion does not contain a header file and the first row is blank, hence a separate data definition is required (INDD) and the data rows start at line 2 (STARTROW):
!INTEXT &INDD(my_dd),
&SETTINGS(dd_settings),
&OUT(convertedDMfile),
@STARTROW=2.0
filetoconvert.csv
Related topics and activities