
Introduction to Declustering
Declustering is an important step in the resource estimation process to ensure that all samples’ weights are equal, relative to the area that they inform. Supervisor uses a method of declustering known as cell declustering, where weights are assigned to cells on a user-defined 3D-grid, depending on the number of samples within that cell. This means that samples within highly populated cells (clustered data) are weighted less than samples from sparsely populated cells. The cell weights within each cell are normalised to one, with each sample within the cell contributing an equal part of the weight.
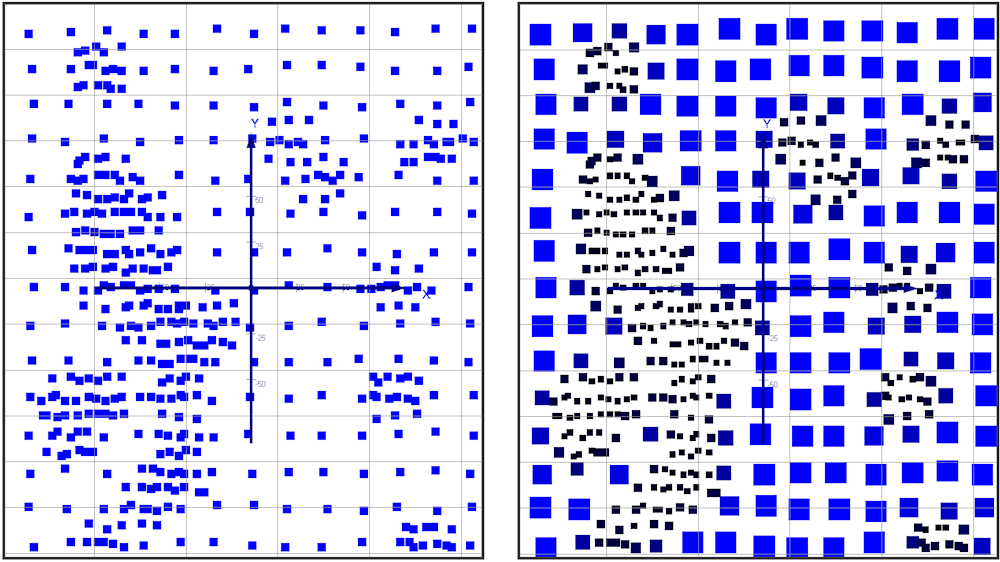
The image below shows a 2D set of data before (left) and after (right) declustering. Before declustering, all of the data points have an equal weighting, meaning that areas with lots of data are overrepresented in the global statistics. After declustering, the clustered points have less weighting (shown by the smaller point size and darker colouring), whereas the points in more sparsely populated areas are weighted more.
This tutorial will guide you through selecting the optimum cell size for weighting data points and then using those cells to decluster a dataset using Supervisor.
| Next» |