
Neighborhood Parameters Definition
This section describes these different rules and parameters. Two types of neighborhoods are offered:
- a Unique neighborhood: When dealing with small datasets, it is possible to use the entire set of data during the interpolation process. This case is referred to as a Unique neighborhood.
-
The main advantage of the Unique neighborhood is that during calculation the kriging matrix inversion is performed once only for all. It remains the same for all the target points while the right-hand-side member of the kriging equations is changing with each target. This means less CPU time for solving kriging equations than with a Moving neighborhood.
In addition, a Unique neighborhood avoids some neighborhood artefacts.
Note: Strictly speaking, the Unique neighborhood, is not compatible with the presence of faults. However the system automatically switches to the pseudo-unique case where for each target, all the points are taken into account, as long as they are visible from the target through the fault system. The algorithm for handling faults is described later in this section.
-
a Moving neighborhood: Given the location of a target point, a Moving neighborhood consists in selecting the best information which could be used in the interpolation or simulation process. The main idea is to get information as regularly spaced as possible around the target, eventually taking anisotropies into account. The selection of the samples is a sequential algorithm applying several criteria which are described below.
Check Moving neighborhood to access the associated parameters. Otherwise a Unique neighborhood will be used for the interpolation.
In the case where the neighborhood is created from the neighborhood explorer (and not from an interpolation task), we have two additional fields to associate data and initialize automatic parameters:
- Optional geostatistical set: Selecting an existing Geostatistical set will automatically select the associated data in the Input data table field. The Geostatistical set is used to parameter the search ellipsoid orientation, taking the same as the one defined for the variogram model, and for the radius size, taking the average range (if the model has several structures) along each direction of anisotropies.
-
Input data table: The selection of an input data table is mandatory to activate:
- the Spread samples over categories option.
- the Capping option
These two options require to define a variable.
The moving neighborhood section offers several possibilities:
- New: Select this option if you wish to create a new neighborhood. You can then modify the automatic parameters.
- Existing: Select this option if you wish to load the parameters of an already existing neighborhood. A Print button enables you to check the content of the neighborhood defined (sent in the Messages window). The neighborhood can be used as it is or you can modify the initialized parameters.
Samples of a Moving neighborhood are selected:
- From an ellipsoid: Given the location of a target point, the neighborhood consists in selecting samples only if they fall inside an ellipsoid centered on the target point. This ellipsoid is defined through its dimensions along its main axes and a possible rotation against the main axes of the study. All the different parameters used for its definition are described below.
- From the target block: This neighborhood is only available for Block kriging. It is a simplification of the neighborhood where all the samples falling inside the target block will be considered as neighbors. All the parameters of the Ellipsoid neighborhood will be greyed out, except the Minimum Number of Samples and the Replace Kriging by Average if Number of Samples inside the Block is greater than options defined in the Shortcuts tab.
The defined neighborhood can be saved (in a new one or overwriting an existing one) by clicking on the Save neighborhood button. We offer a pattern (neigh_%sizeE_%support) to name this neighborhood.
Ellipsoid
Samples are selected in the neighborhood only if they fall inside an ellipsoid centered on the target point. This ellipsoid is defined through its dimensions along its main axes and a possible rotation against the main axes of the study.
- You can define a possible Orientation, i.e. a rotation of the search ellipsoid. To define this rotation, you can refer to the Rotations section help. By default this orientation is the same as the one defined in the Geostatistical set (if required, as in a kriging or in the simulations for example).
- A sample is kept in the search ellipsoid if the distance between the target and the sample is smaller than a given value. This maximum distance is expressed as 3 maximum distances parallel to the 3 main axes of the ellipsoid. Enter the values for these 3 maximum distances in the U, V, W boxes (U, V, W standing for the rotated X, Y, Z). These distances are expressed as a Radius of the ellipsoid. By default the radius is equal to the average range defined in the Geostatistical set (if the model has several structures) along each direction of anisotropies.
-
The application calculates the distances between each sample and the center of gravity of the target to sort the samples. These distances can be calculated in two different ways:
- If you leave the option Anisotropic distance (according to the ellipsoid) clear, the distances will be isotropic standard distances;
-
If you select the option Anisotropic distance (according to the ellipsoid), the distances will be anisotropic and calculated taking into account the neighborhood ellipsoid parameters:

where du, dv and dw correspond to the components of the distance along the three axes of the new system, and:

where dmax is the greatest of the three distances maximum distance along u, maximum distance along v and maximum distance along w.
The anisotropic distances can be useful for example in 3D to take samples horizontally at a greater distance than vertically. All the samples located on the boundary of the ellipsoid are considered to be at the same distance from the target point, while all the samples falling outside the ellipsoid will never be selected.
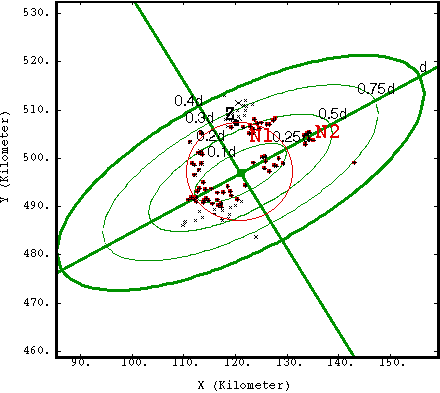
Note: This principle leads distances to be distorted during the search procedure. This behavior is illustrated in the following figure. Two points situated at the same distance from the target point will not necessary be included together in the neighborhood (see point Z and N1 on the red circle - N1 is selected as a possible neighbor, Z is not, although they are at the same distance from the target node).
As a matter of fact, all the points situated on the same ellipsoid are considered as being at the same distance from the target point. That explains why samples are preferentially selected along the bigger axis of the ellipsoid (see N2 which is further from the target node than Z but is selected).
In this example, search radii were defined as maximum distance along u=d and maximum distance along v=0.4d. The maximum number of samples per sector was set at 20.
-
The ellipsoid can be split into different angular sectors inside which the neighbors are grouped. Enter a value for the number of sectors in the Number of angular sectors box. This parameter is used in combination with the Maximum number of samples per sector (see below).
You can increase the number of angular sectors in order to make sure that some samples are selected in different directions of the field. This is particularly useful when the sampling pattern is highly anisotropic.
-
The search of samples in the different sectors is a sequential process. The application scans all samples sorted by distance to the target. The sample can be considered as a valid neighbor if it is contained in the ellipsoid, and if the sector it belongs to does not already have reached its maximum number of samples. Enter a value for this maximal number of neighbors per sector in the Maximum Number of Samples per Sector box. The only reasons when the maximum per sector can be exceeded are:
- in the case of heterotopic search (checked from the Advanced selection tab), to fulfill the requirement, adding extra samples in each sector to have all variables valuated.
- in the case of Select all samples in the target cell/block, when using Block kriging, that just takes all the samples of the cells, regardless of other criteria.
- If needed, you can Split ellipsoid vertically the angular sectors. This will actually double the total number of sectors. This option is only valid in 3D.
- Select the Display neighborhood ellipsoid toggle to preview your neighborhood in a defined 3D scene. In picking mode, you can pick an axis to move the ellipsoid along, or move staying in an ellipsoid plane (UV, UW, VW). This preview option is not available in the Kriging task where a more complete neighborhood test window is offered.
Advanced Selection
This tab groups advanced parameters used to refine the neighborhood.
-
When performing a multivariate neighborhood search, some variables may be undefined for some of the samples. This is called the heterotopic case. Conversely, the isotopic case indicates that all the variables are defined for all the samples.
- Leave the option Apply heterotopic search clear if you wish to perform a standard neighborhood search, that is, the maximum number of samples will be reached for each sector although the selected information may not be convenient for the cokriging process. This is the case, for instance, when one of the variables is not sufficiently represented.
- Select the option Apply heterotopic search if you wish to get more information from the variables which are defined on less samples. A preliminary step is added which still looks for the nearest samples in each sector, but tries to get all the variables informed whatever the number of samples needed to fulfill this additional requirement. Each variable will be informed in at least one of the selected samples of each sector. After this step, the search goes up in a standard way.
-
Select the option Select all the samples in the target cell/block if you want all the samples falling inside the target cell/block to be considered as neighbors. If you leave this option clear, the points inside the target cell/block will be kept in the neighborhood only if the distance or maximum number requirements are satisfied. This option is only available in the case of block kriging.
This option is not visible in Estimation per Domain of the Resources Workflow but it is always activated.
- When samples are densely organized along lines, increasing the count of angular sectors is not always sufficient to stabilize the neighborhood. Select the option Minimum distance between two selected samples if you wish to counterbalance any clustered configuration. As soon as one sample has been selected, it will not be possible to select any other sample located within a given distance. Enter the value for this minimum distance in the next box which becomes active.
- Define a Maximum number of samples to include in the neighborhood search. This option will speed up the neighborhood calculation. The search will tend to use the nearest samples in all sectors until the maximum per sector is reached OR this global maximum is.
-
Select the option Spread samples over categories if you wish the samples to be distributed in a homogeneous way among categories, defined by a Categorical variable, and not only issued from the closest points to the target. For example, if you want to select an optimum number of samples per borehole, you can define the variable LINE ID as the categorical variable.
-
Number of samples per category:
- Optimum: Enter the value for this optimum number of samples in the next box which becomes active. Two passes may be performed. On the first pass, no more than the optimum number of samples per category will be selected. If the maximum number of samples per sector has not been reached, then a second pass is performed to try to reach this maximum.
- Maximum: Enter the value for this maximum number of samples in the next box which becomes active. If a given number of samples has been selected for a category, it will not be possible to select any other sample from this category even if the maximum number of samples has not been reached.
-
Number of categories:
- Minimum: Enter the value for this minimum number of categories in the next box which becomes active. If the minimum number of categories has not been reached, the estimation is not performed. This parameter is a shortcut.
- Maximum: Enter the value for this maximum number of categories in the next box which becomes active. If samples belonging to a given number of categories have been selected, it will not be possible to select a sample which belongs to any other category.
In Estimation per Domain of the Resources Workflow, these two options are respectively named Optimum Number of Samples per Drillhole and Maximum Number of Samples per Drillhole. No Categorical Variable is required because the drillholes name is automatically selected.
-
Shortcuts
These different parameters represent conditions for avoiding estimation to be performed. The neighborhood search will fail and the estimated value for variable(s) at the target point will receive an undefined value.
-
Set a value for the minimum number of neighbors in the Minimum number of samples box. If the actual number of samples that fall inside the ellipsoid is smaller than this value, the neighborhood search fails and the estimated variables at the target point receive an undefined value.
This option is one of the two available options in the case of the From the target block mode.
- Most of the interpolation processes are not designed to work satisfactorily in extrapolation. Select the option Maximum distance without any sample to possibly interrupt the neighborhood search if no sample can be found within a given distance from the target. Enter the value for this maximum distance in the next box which becomes active.
-
In order to avoid a one-sided neighborhood which may lead to unstable estimations, select the option Maximum number of empty sectors to possibly interrupt the neighborhood search when there are too many empty sectors. Enter the value for this maximum number of empty sectors in the next box which becomes active. The empty sectors can be consecutive or not. This Consecutive option can be useful to avoid extrapolation on borders of the data area.
- Checking the Consecutive option: if the Split ellipsoid vertically option is active, the number of consecutive empty sectors check will be done twice. If one of the upper or lower split has too many empty sectors, no estimation occurs.
- Unchecking the Consecutive option: if the Split ellipsoid vertically option is active, the number of empty sectors check will be done globally. If the neighborhood has too many empty sectors, no estimation occurs.
-
Select the option Replace estimation by the average if number of samples inside the block is greater than to replace the estimation operation by a simple arithmetic average when the selected number of samples inside the block in the neighborhood is greater or equal than a given value. Enter the value for this maximum number of samples in the next box which becomes active. This option is only available in the case of block estimation on a Grid data table.
This option is only available in Block mode and requires to select the Select all samples in the target cell/block option at the same time.
This option is one of the two available options in the case of the From the target block mode.
This option is not available in Estimation per Domain of the Resources Workflow.
-
The option Use the value of one sample which is inside the proximity rectangle is only available in the case of Point Kriging. It is designed to copy the value of the variable from one sample to the target point, provided that the sample is inside the proximity rectangle centered on the target point. This avoids performing the kriging when many nodes are already informed.
This option is not available in Estimation per Domain of the Resources Workflow.
Note: The first close enough sample, which is not necessarily the closest, is kept.
Note: If the proximity distance is set to zero, this option is ignored.
Capping
The Capping tab enables you to apply thresholds on variable values to avoid too large or too small estimates. Only samples located on or further than the defined ellipse (in 2D) or ellipsoid (in 3D) will apply the cutoff.
Capping can be applied to multiple variables simultaneously depending on the input variables. Each variable is managed in its own tab, named after the corresponding variable. For each variable, you can define specific capping parameters, including two capping options - Low capping and High capping - each with its own threshold and associated parameters, as well as the corresponding no-capping distances.
When creating or editing a neighborhood (through the Neighborhood Explorer), a ![]() button allows you to add new tabs corresponding to the capped variables. Clicking this button opens a Data Selector, where you can select several variables at once - a new tab will be created for each selected variable.
button allows you to add new tabs corresponding to the capped variables. Clicking this button opens a Data Selector, where you can select several variables at once - a new tab will be created for each selected variable.
If a sample located beyond the defined No capping distance has a value greater or smaller than the specified Threshold, the value of the variable will be replaced by the threshold, or the sample will be ignored, depending on the selected mode. You can choose to:
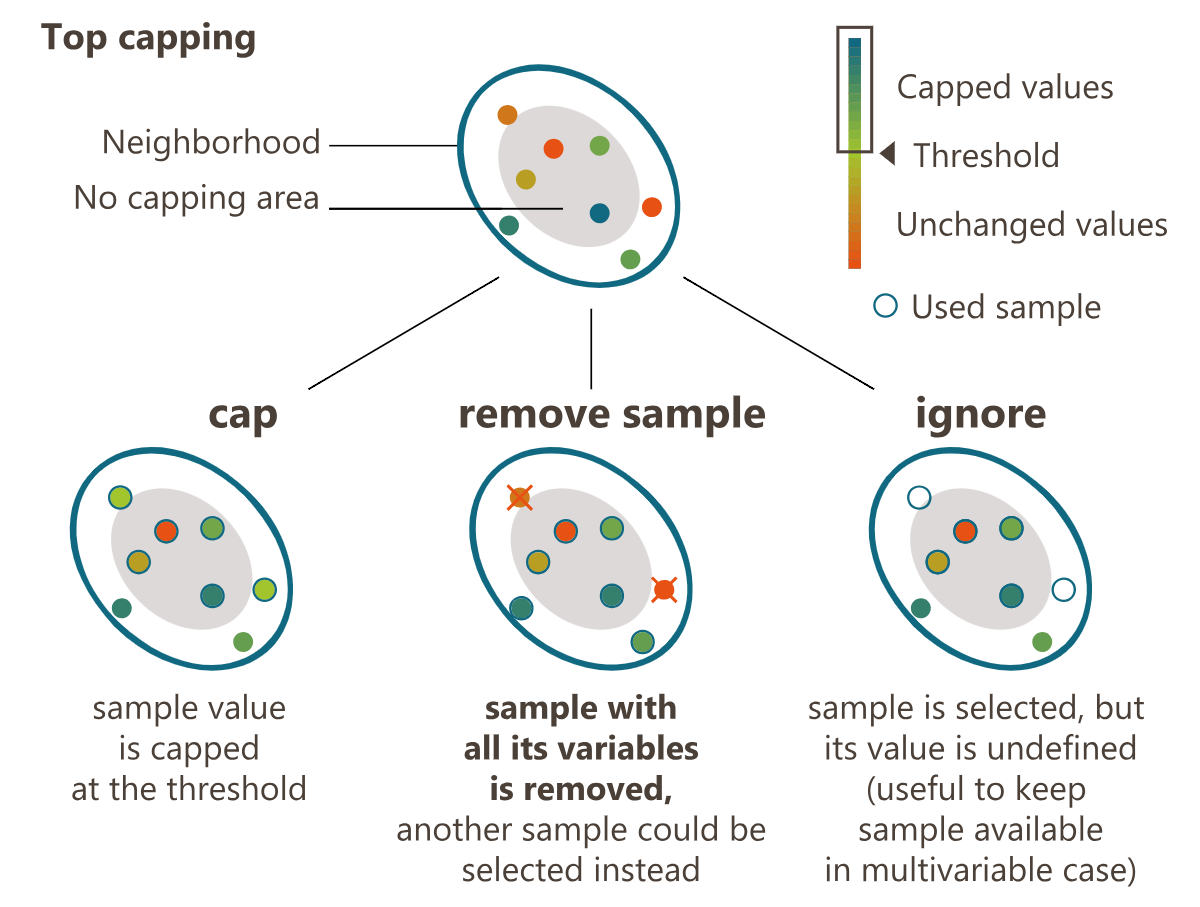
- Cap: replace the value by the threshold.
- Remove sample: completely remove the sample from the list of the neighborhood candidates. This mode applies to one variable only. In the multivariate case, if several variables are set to Remove, an error message will be displayed.
- Ignore: keep the sample as a neighbor but set its variable value to undefined. When used in the multivariate case, the values of the other variables remain unchanged. This option generally assigns a zero weight to the sample for this variable during estimation, but the other variables are still considered.
Note: Only capped variables (i.e. those for which the capping option is activated) are saved in the neighborhood, including when processing in batch mode.
However, variables associated with the geostatistical set are always displayed in the Capping tab (visible as tabs), even if capping is not applied to them.
Note: When applying the neighborhood to another dataset, the variable used for capping must exist in this dataset with the same name. If the corresponding variable is not found, a warning message is displayed and no capping is applied to that dataset.
Two options are available to simplify distance configuration:
- Same no-capping distance for all variables: applies the same Low and High no-capping distances to all variables for which capping is activated.
- Isotropic no-capping distance: uses a single distance value for all directions U/V(/W). When this option is selected, only one distance field is displayed, and the same distance is applied isotropically.
Note: By default, the automatic distance is equal to 25% of the radius defined for the ellipse / ellipsoid along each direction. For example, if you create an ellipsoid of 100x100x20m, the automatic capping distances will be of 25x25x5m.
Nested
This tab enables you to sequentially apply different search neighborhoods.
You can define the neighborhoods either with factors from the reference ellipsoid, or directly the radius of the different ellipsoids, following each direction U, V and W.
The neighborhood defined with the parameters on the other tabs is the "Standard Neighborhood". In this tab, you can define a Medium and a Large neighborhood. These two additional neighborhoods are defined with an ellipsoid, but also two additional parameters that are the Minimum number of samples and the Maximum number of samples per sector.
The Minimum Number of Samples must be less than or equal to the product Number of sectors * Maximum Number of Samples per Sector (*2 if Split Ellipsoid Vertically is checked).
It is also possible to use an Infinite neighborhood to interpolate all the target points of your output file. This option needs to be activated in the check-box.
Note: The iterating algorithm for the neighbor search is as follows:
- The Cutoff for large values is applied first (if the sample point is at a distance greater than a given distance, and if its value is greater than a given value, the data point is assigned the cutoff value)
- Then, the Proximity rectangle criterion is tested (the 1st point is kept in the Proximity rectangle)
- All the samples outside the ellipsoid are then discarded
- The points inside the ellipsoid are sorted according to their distance to the target point
- In the heterotopic case, for each variable and sector, we will keep the closest sample informed for this variable as a neighbor. This might cause the Maximum the points where all the variables are not informed are discarded
- For all samples sorted by distance, determine associated sector and keep sample as a neighbor if the Maximum number of samples per sector for this sector is not yet reached
- When the loop is finished for all the sectors, the criterion Maximum number of consecutive empty sectors is checked.